(It's a repost from https://www.invicti.com/blog/web-security/testing-saml-security-with-dast/)
Testing the security of your SAML-based single sign-on infrastructure is a vital but also difficult and tedious task. This technical post presents the basics of SAML security and shows how automated security checks developed by Invicti are making it possible to scan for some of the most common SAML security issues.
Single sign-on (SSO) is the foundation of secure access to modern web application environments, allowing users to log in once and apply that authentication to multiple other applications. One of the most common ways to implement SSO is using SAML, or the Security Assertion Markup Language – an open standard for communicating authentication and authorization requests and responses between systems. Any weaknesses in how your application handles SAML messages could compromise your web application, so SAML security is a vital consideration.
In the past, checking SAML endpoint security was only possible through painstaking manual testing – but that is changing. This post presents an overview of SAML security testing, introduces new security checks in Invicti’s Acunetix Premium vulnerability scanner, and shows how advances in dynamic application security testing (DAST) are making it possible to partially automate SAML security testing.
A brief introduction to SAML and SSO
SAML is a complex format for exchanging security-related data in a variety of situations. In practice, SSO is by far the most common use for SAML today, so let’s start with an overview of a typical SAML message flow in an SSO situation for a web application.
Three parties are involved in a SAML data exchange: a user agent (such as your web browser), a service provider (SP), and an identity provider (IdP). In everyday terms, the service provider is the application you want to access and the identity provider is the system that can authenticate you. Figure 1 below shows the SAML messages that are exchanged to get you logged into the application through SSO.
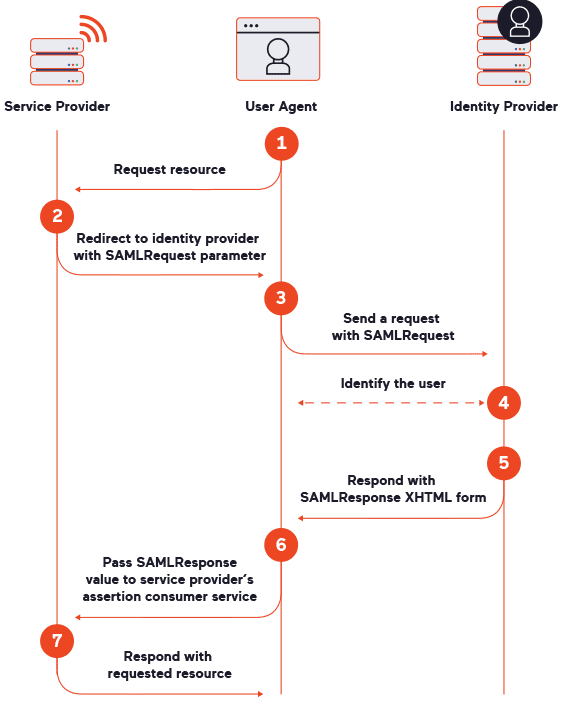
To summarize, you start by requesting access to an application using
external authentication (for example, by clicking a button to log in
with Google). The application takes your request and redirects you to
the identity provider (such as Google) with a SAMLRequest
parameter for authentication. After you’ve logged in (or if you are
already logged in there), the identity provider returns a form with a SAMLResponse
parameter to confirm your identity, and your browser automatically
passes it on to the application. Assuming everything is valid and you
are authorized to access the application, your browser is granted
access.
The two most important types of SAML messages that we will work with for security testing are SAMLRequest and SAMLResponse.
The SAML response includes (among other elements) a signature in XML
Signature (XMLDSig) format, and that signature is obviously a critical
component for security (and for vulnerability testing). We will also be
talking about testing SAML consumer endpoints – in this context, these
are URLs within the service provider application that are used to
receive SAML messages.
Approaches to automating SAML security testing
SAML is a very complex technology, so to test for SAML vulnerabilities, we need to look at the various possible attack surfaces, see what attacks and vulnerabilities are possible where, and what testing methods we could apply.
Working from the ground up, we know SAML is an XML-based language that relies on a multitude of related technologies, such as XSLT and XMLDSig, each with its own large attack surface, so we can play with a variety of XML-related attacks. Secondly, there could be vulnerabilities related to SAML itself, namely its implementation and configuration. And finally, there are logical vulnerabilities in how SAML and the data it provides are used in a particular system. So to fully and qualitatively test a particular SAML implementation across all these areas requires a lot of manual pentesting by an experienced tester with specialized skills and knowledge.
While some issues, such as logical vulnerabilities, will always require manual testing, we have implemented vulnerability checks for Acunetix Premium that provide the first step towards automated security testing for some of the most common attacks on SAML, namely attacks targeting the service provider. Depending on the vulnerability type, some attacks are only possible after authentication, while others can be tested anonymously. Let’s dive into the SAML security checks we have added to Acunetix Premium.
Testing for misconfigurations related to the SAML signature
One of the most important security elements of SAML is the XML Signature of a message. Not surprisingly, a large number of attacks on SAML specifically focus on the signature, notably many variants of XML Signature wrapping. One of the new security checks in Acunetix tests whether the application is vulnerable to two of the most common signature-related weaknesses: missing signature verification and signature exclusion.
Prerequisite: Authenticating the scanner to get a valid SAMLResponse message
To properly test for signature-related vulnerabilities, we need to be
able to authenticate with the application. This is necessary because
it’s the only way to obtain a valid SAMLResponse message to manipulate, and this requirement applies to both manual pentesting and automated tests.
For scanning with Acunetix specifically, this means first adding a suitable sequence in the Logic Sequence Recorder (LSR) that includes the SAML authentication process. As an Acunetix user, you follow the usual LSR process: start the LSR recording, open the target URL, log in to the target site, authenticate with your identity provider when redirected, and then return to the target. Everything is as usual, with no additional settings. Following the same principle, you can also create an LSR authentication sequence initiated by the identity provider (this approach supports both Redirect-POST binding and POST-POST binding). In all cases, the scanner automatically detects if SAML technology is used under the hood and only runs the check if the target is in scope. That way, you don’t need to worry about attempting to scan an identity provider or even (in more complex authentication configurations) a third-party or out-of-scope service provider.
Assuming you’ve enabled the SAML signature check in the scan profile
and added the relevant LSR sequence, Acunetix will run that sequence
during the scan to perform all the necessary steps and receive all the
SAML-related requests. Once the sequence reaches step 6 in figure 1, the
scanner can obtain both a valid SAMLResponse message and
the target’s response to that message (step 7). Now we can start
checking for various signature verification vulnerabilities.
Testing for signature exclusion and missing signature verification
One of the most common SAML vulnerabilities is missing signature verification, where the service provider receives a signed SAMLResponse
message but doesn’t check the signature at all. This common issue isn’t
caused by a problem with the implementation of a particular SAML
library but by misconfiguration – it’s not unusual to disable signature
verification when developers test the SAML implementation and then
forget to enable it at the end. At first glance, the application works
as normal, and it is hard to see the problem because the SAMLResponse message from the identity provider arrives correctly signed, is accepted, and everything looks fine.
To check for insecure behavior, our security check (SAML signature audit) modifies the DigestValue element (see figure 2), making the signature invalid. If the target responds in a similar way as for a valid SAMLResponse
message despite the changed signature, we can assume that the service
provider does not check the signature. In modern web applications, it is
difficult to directly compare responses due to their dynamic nature. To
confidently detect whether an application has accepted or rejected a SAMLResponse message, we use a complex content-type-dependent algorithm for response comparison, as well as some additional checks.
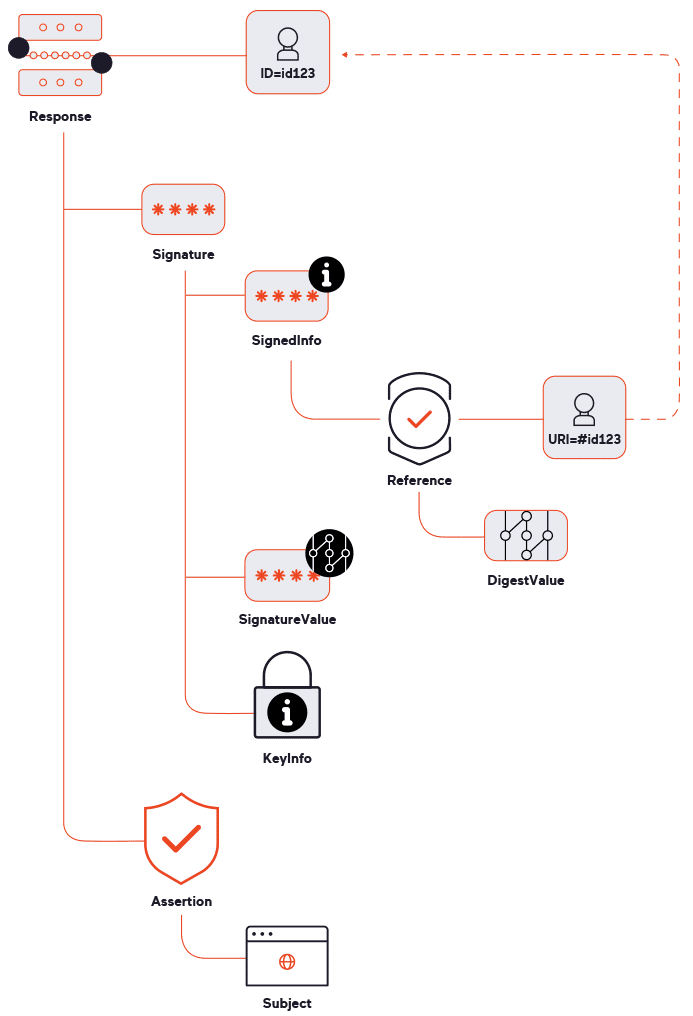
Another security check attempts to perform a closely related attack:
signature exclusion. If successful, this can reveal a similar SAML
misconfiguration as with missing signature verification or even signal a
vulnerability in the actual SAML library used by a service provider.
Instead of merely modifying an existing signature, this check completely
removes the Signature element (the full Signature
branch in figure 2). Once again, we then compare how the application
responds to the modified response versus a valid one and report a
vulnerability if the unsigned message is not rejected.
Testing SAML consumer endpoint security
The second set of checks (SAML consumer service audit) performs anonymous tests for various vulnerabilities in the Assertion Consumer Service (ACS) endpoint of the service provider. We will look at the specific tests in a moment, but because we are now doing anonymous testing, we first need to find a way to find out what we are going to test.
Prerequisite: Getting a SAMLRequest message to test anonymously
One of the difficulties with SAML is that it is quite tricky to do any black-box testing on it, even manual pentesting. As shown in figure 1, the flow is that the service provider redirects the user to the identity provider, which then returns a message for the service provider. The crucial point is that, in most cases, the identity provider returns the user not to the same path from which the request was sent (step 1) but to a different location on the service provider – specifically, to the ACS endpoint. For example, the user might initially access /auth/login in step 1 but then be sent to a location like /saml/acs in steps 5 and 6. So for security testing, we need to probe this second endpoint on the service provider, not the initial one.
The problem here is that we need to somehow discover the actual path
for testing the service provider ACS. Normally, we would get this path
in step 5 after authenticating with the identity provider – but we’re
testing anonymously, so we need to discover the endpoint without the
need to authenticate. Luckily, we can solve this issue by parsing the SAMLRequest value received from the service provider in step 2. This contains a SAML AuthnRequest
element (encoded in base64 and compressed using Deflate) where the
service provider introduces itself to the identity provider and says
what response (assertion) it wants to get and where this should be sent.
Here is a sample SAMLRequest document to show you how this works:
Parsing the AuthnRequest value, the identity provider looks at the content of the saml:Issuer element to learn what service provider sent the request (sp_name in this example). We can also look at the optional (but commonly included) AssertionConsumerServiceURL attribute to discover the expected ACS path on the service provider – in this example, it is http://sp_name.com/acs.
The Acunetix scanner uses this information to trigger and run SAML
consumer endpoint security checks. Specifically, the checks are only run
if, during crawling, Acunetix encounters a SAMLRequest message (Redirect Binding) that contains an AssertionConsumerServiceURL attribute.
The remaining AuthnRequest elements can also be very
useful for manual pentesting to help us understand exactly what elements
(attributes) the service provider expects to get in the assertion. The Destination attribute also tells us what identity provider is used, which helps to infer (especially for typical products) the location of SAML metadata, including the X.509 certificate and its Issuer value. So in some cases, we can collect enough data manually to create a correct SAMLResponse
message (without a valid signature, of course) for a given service
provider completely from scratch. This is useful for test attacks
related to signature checking, including signature exclusion and
certificate faking.
DAST security checks for SAML consumer endpoint vulnerabilities
At this point, the scanner knows the ACS URL and is able to probe the SAML consumer endpoint for vulnerabilities. The tests look for security issues related to the SAML library implementation, so we’re working with the steps preceding signature verification in the process. Let’s see what vulnerabilities can be identified automatically by Acunetix.
XXE injection vulnerabilities
SAML is an XML-based language, so the service provider needs to parse an XML document before it does anything else. Thus, we can test for XXE injection vulnerabilities without even forging a valid fake SAML message (because parsing needs to happen before any validation). Acunetix tests for XXE vulnerabilities in SAML consumer endpoints – and before you say XXE is no longer a threat, such vulnerabilities do still occur (see CVE-2022-35741 in Apache CloudStack SSO as an example).
XSLT injection vulnerabilities
After receiving a SAMLResponse message, the service
provider needs to run some transformations on the SAML document using
XSLT, exposing yet another attack surface. To check this, Acunetix
inserts a typical XSLT attack payload in the Reference element of the signature (see figure 2 for the signature structure).
SSRF vulnerabilities
The KeyInfo element is the part of an XML Signature
(XMLDSig) used to obtain the key needed to validate the signature. For
security testing, one very interesting feature of KeyInfo
is dereferencing – the ability to specify the key location as a path to a
local file or a remote URL. To any pentester, this immediately signals
opportunities for at least a blind SSRF attack. This insecure feature
has no place in any hardened SAML implementation, yet it may still be
present in some modern implementations. What’s more, in certain cases,
it is also possible to read local files using XSLT transformations.
Real-life vulnerabilities related to KeyInfo include CVE-2021-40690 in the widely-used Apache Santuario library and CVE-2022-21497
in Oracle Access Manager (and some other Oracle products). If you are
interested in this topic, I recommend two blog posts about exploiting
these Santuario and OAM vulnerabilities. Acunetix uses several payloads to test for both these CVEs and similar variations of support for this feature.
XSS vulnerabilities
Although it is encoded, the SAMLResponse parameter is
still user input and could potentially be abused to perform injection
attacks, so Acunetix also includes checks for XSS vulnerabilities. This allows us to detect vulnerabilities similar to CVE-2020-3580 in Cisco ASA, where the server response includes the SAMLResponse value.
Interestingly, many SAML libraries check the values of some SAMLResponse attributes before validating the signature. For example, they check the value of the saml:Issuer element that indicates which identity provider sent the given response (similar to the same element in AuthnRequest).
If the target then returns this value in error messages without proper
encoding, an XSS vulnerability may result, so we need to test for it.
(As a side note, the scanner doesn’t know the correct saml:Issuer value for the identity provider, but it can still run the security check using the Destination value from AuthnRequest, as that works for some common identity providers).
An important point is that we’re working with XML, so whenever you’re
injecting XSS payloads into SAML attributes, you need to correctly
encode them using entity references to avoid problems with XML parsing
and schema validation for the SAMLResponse message. For the Destination attribute, which should point to the ACS URL, an XSS payload also needs to be a valid URL, for example:
One small step for automating SAML security testing
Testing the security of SAML data processing and signature verification is crucial if you want to be sure that your single sign-on infrastructure is secure. Considering the complexity of manual testing, automating the process is a convenient way to perform systematic SAML security testing. The current Acunetix Premium release adds new security checks to help you automatically find the most common vulnerabilities related to SAML processing and signature verification. While this is already a significant step towards improving SAML security, it is only the first step for us at Invicti, as we are already working on adding more SAML checks for our products. We are also looking forward to getting user feedback on the checks added with the current release.